# 並行処理?並列処理?
並行処理とか並列処理って一体なんなのでしょう.
黎明期の計算機では,並行処理だの並列処理だのなんてことは,一切考えていませんでした.入力された命令を1つずつ,真面目に実行していくことで計算を実行していたのです.黎明期の計算機は,人間が紙と鉛筆でちんたら計算をするよりも,何倍も高速にかつ正確に計算をすることができたので,とても人気になりました.ただ,その当時の計算機は物理的にサイズもデカくて高価なものでした.なので,計算機を導入・設置できるのは大学などのお金と部屋が余っている組織ぐらいしかなかったわけです.
大学に計算機が設置されると,大学の研究者たちは喜びました.これで面倒な手計算から解放されるわけですからそりゃそうでしょう.みんなでこぞって計算機を使いたくなります.でも「計算機を利用したい研究者の人数」が「設置してある計算機の台数」と比較して圧倒的に多いので,計算機の使用を巡って争奪戦が起こります.だって,当時の計算機は「入力された命令を1つずつ,真面目に実行していく」タイプの計算機なので,他の誰かが計算機に計算をさせている間は,他の研究者はその計算機を使うことができないからです.そんなの不便すぎます.せっかく便利でしかもめちゃんこ高価な計算機が設置してあるのに,しかも使いたい人はたくさんいるのに使わせてあげられないなんて,もう不満タラタラです.そこで研究者たちは考えました.
「どうやって1台の計算機を複数人で共有して使うことができるだろうか?」
「1台の計算機で複数のタスクを処理するためにはどんな仕組みが必要なんだろうか?」
ここからoperating systemとかprocessとかいろんな概念が確立されていくわけです.
「並行」というのは,英語ではconcurrentに相当し,「1台のマシンで複数のタスクを同時に実行している(ように見える)様」を意味します.concurrentな処理は「限られたリソースを有効活用すること」を目的としていて,現在の計算機では「同時に処理しているように見せるために,複数のタスクを時間的に細切れにして全部のタスクをちょっとずつ進める」ことでconcurrentな処理を実現しています.
一方で,似たような概念として「並列」というものもあります.英語ではparallelに相当し,「複数台のマシンで1つのタスクを実行している様」を意味します.parallelな処理は「(複数のマシンという)豊富なリソースを利用して1つのタスクを高速に実行すること」を目的としていて,concurrentとは目的が違います.
# concurrentなプログラム
ここまで計算機の進化の歴史を本当にざっくり見てみましたが,じゃあconcurrentという概念がプログラムとどう絡んでいくのでしょうか.
プログラムというのは大体「CPUでの演算」「データのI/O」「ネットワーキング」を部品として構成されています.それぞれの部品には特徴があって,「CPUでの演算」はとても高速に実行できるけれども,「データのI/O」と「ネットーワーキング」は(「CPUでの演算」と比較して)桁違いに,本当に桁違いに時間がかかります.もし計算機が「入力された命令を1つずつ,真面目に実行していく」方式で動いていたとすると,「データのI/O」と「ネットーワーキング」に取り組んでいる間,計算機はうんともすんとも言わずに黙り込んでしまうことになります.これは明らかに無駄です.CPUは何も計算を進めないでただ存在しているだけになるわけです.
concurrentという概念の背景には「どうやって1台の計算機を複数人で共有して使うことができるだろうか?」という問題があったわけです.この問題意識が一歩進むと,「1台の計算機で複数のタスクを処理するためにはどんな仕組みが必要なんだろうか?」となり,さらに一歩進んで「(複数のタスクで構成される)1つのプログラムを1台のCPUで効率的に処理するためにはどういう仕組みが必要なんだろう?…そうだ!CPUが暇な時間帯には別の仕事をさせよう!」となるわけです.
「時間がかかってしまう処理をやっている間に,他にできる計算をCPUにやらせよう」というのがconcurrentなプログラムを書きたい理由です.だってそうした方がやりたいこと早く終わるでしょう.しかもPersonalな計算機が世の中に普及して「計算機はより高速にユーザーの動作に応答しなきゃいけない(うんともすんとも言わない計算機は嫌われてる)」し「ユーザーは大抵の場合音楽聴きながらメールチェックしつつYoutubeで動画も見たいワガママな存在」なので,CPUに暇な時間なんてものはないわけですよ.
「プログラムはconcurrentに実行されるべき」となるとconcurrentなプログラムを記述して,それを実際にconcurrentに実行する機構が必要になります.
「実際にconcurrentに実行する機構」についてはOperating Systemが頑張って,プログラムがconcurrentに実行されるように実行環境を提供します.Operating Systemは結構頑張るのですが,やっぱり頑固なハードウェアさんとやりとりしないといけないので,相当大変そうです.提供してくれる実行環境の効率にも限度がありそうです.
「concurrentなプログラムを記述」するところについては,プログラミング言語の守備範囲なわけですが,いろんな言語がいろんなアプローチを取って,concurrentなプログラムをより簡単に書けるように,プログラム開発者に部品primitiveを提供してくれます.
でも古参のプログラミング言語たちは,そのデザインの根幹に「プログラムがconcurrentに実行される」とか想定していないわけで,いざやろうとすると不自然なところとかがやっぱりでてきてしまいます.なのでgolangは,言語のデザインの段階でconcurrencyを考慮した言語として誕生しました.そうすれば,concurrentなプログラムがより直感的にわかりやすく書けるようになるわけです.
# goroutineとchannel
golangはconcurrentなプログラムを書くためのprimitiveとしてgoroutineとchannelを提供しています.というのもgolangでは,concurrentなプログラムを「goroutineたちがメッセージをやりとりしながら進行する計算」としてモデル化しているのです.ここで注意しておきたいのが,concurrentなプログラムを表現する別のモデルも考えられるという点です.モデル化にはバリエーションがあるので「goroutineたちがmessage passing」だけが唯一のモデルというわけではないです.
goroutineというのは,概念的にはOSの提供するプロセスとかスレッドみたいなもので,実行中の処理を抽象化したものです.直感的にはOSのスレッドと思っていてもいいかもしれません.実態はちょっと違うんですけどね.この「抽象化された処理」同士がmessage passingによって情報を共有することでconcurrentな処理が実現できることになります.
channelというのは,goroutine間でのコミュニケーションをサポートするためにメッセージキューです.
golangは言語設計の根底にある思想として
Don’t communicate by sharing memory, share memory by communicating.
を,掲げています.要するに「goroutineたちは共有メモリを設けるのではなくてmessage passingでコミュニケーションをとる」ように設計しようということです.
# goroutineとchannelの設計と実装を眺める
# goroutine
goroutineは「実行中の処理を抽象化したもの」と書きましたが,これは具体的には「計算に用いるstackと実行状態を保持している構造体」として実装されています.
| |
「それってOSの提供するプロセスとかスレッドと同じじゃないの?」
それは確かにそうなんですが,goroutineはOSの提供するプロセスとかスレッドと同レベルの存在ではなくて,goroutineは,OSの提供するスレッドに対してM:Nでマッピングされる「golangのruntimeが提供する,ユーザー空間で定義されたスレッド」として存在しています.golangのruntimeはgoroutineを管理していて「いつ,どのgoroutineを実行するか」を決定するschedulerとしての役割も担っています.つまりgolangのruntimeはユーザー空間で動く「ミニOS」のようなものな訳です.とは言いつつも,実際に実行されるためにはOSの提供するスレッドとして実行されなければいけないわけですから,goroutineはスレッドにマッピングされることになります.golangのschedulerはgoroutineとOSのスレッドを,M:Nでマッピングします.つまり複数のgoroutineが複数のOSスレッドとして実行されるわけです.1つのgoroutineが複数のOSスレッドとして実行されるし,1つのOSスレッドでは複数のgoroutineを実行することになります.

OS Process v.s. OS Thread v.s. Goroutine
となると,重要なのは「golangのruntimeがどのようなルールでgoroutineの実行計画を立てるのか」です.
# golangのruntimeによるgoroutineのスケジューリング
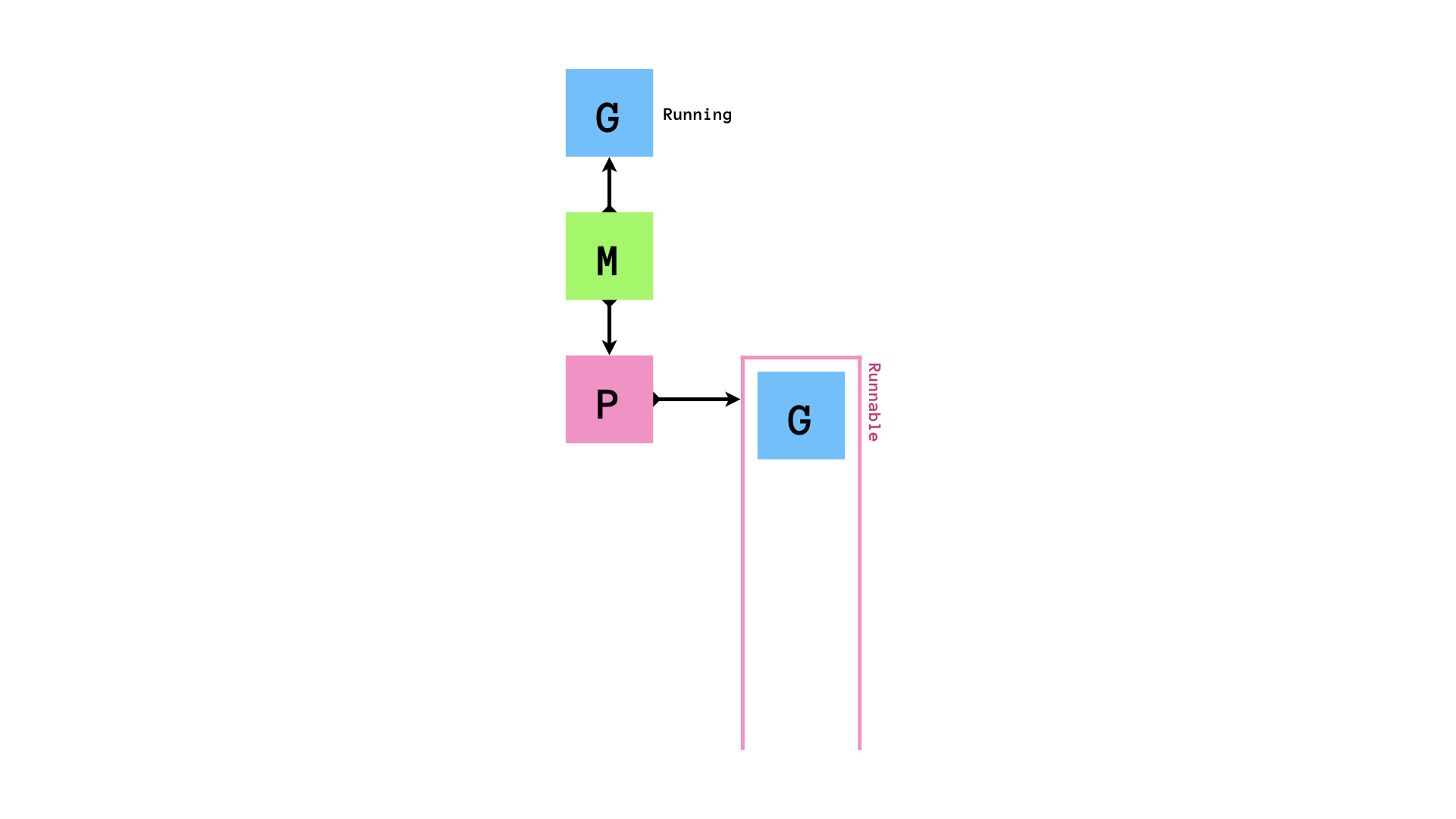
登場するのはM,G,Pの三人.
M- machineの
M - OSスレッドに相当する
- machineの
G- goroutineの
G
- goroutineの
P- processorの
P - スケジューリングのコンテキスト(次どの
Gを実行するのか)を管理している - 具体的に言えば,runnableなgoroutineのキューを管理しているのが
P
- processorの
`G`,`M`,`P`
まず,環境変数GOMAXPROCSの数だけM,Pがセットされます.以下では,GOMAXPROCS = 2とします.
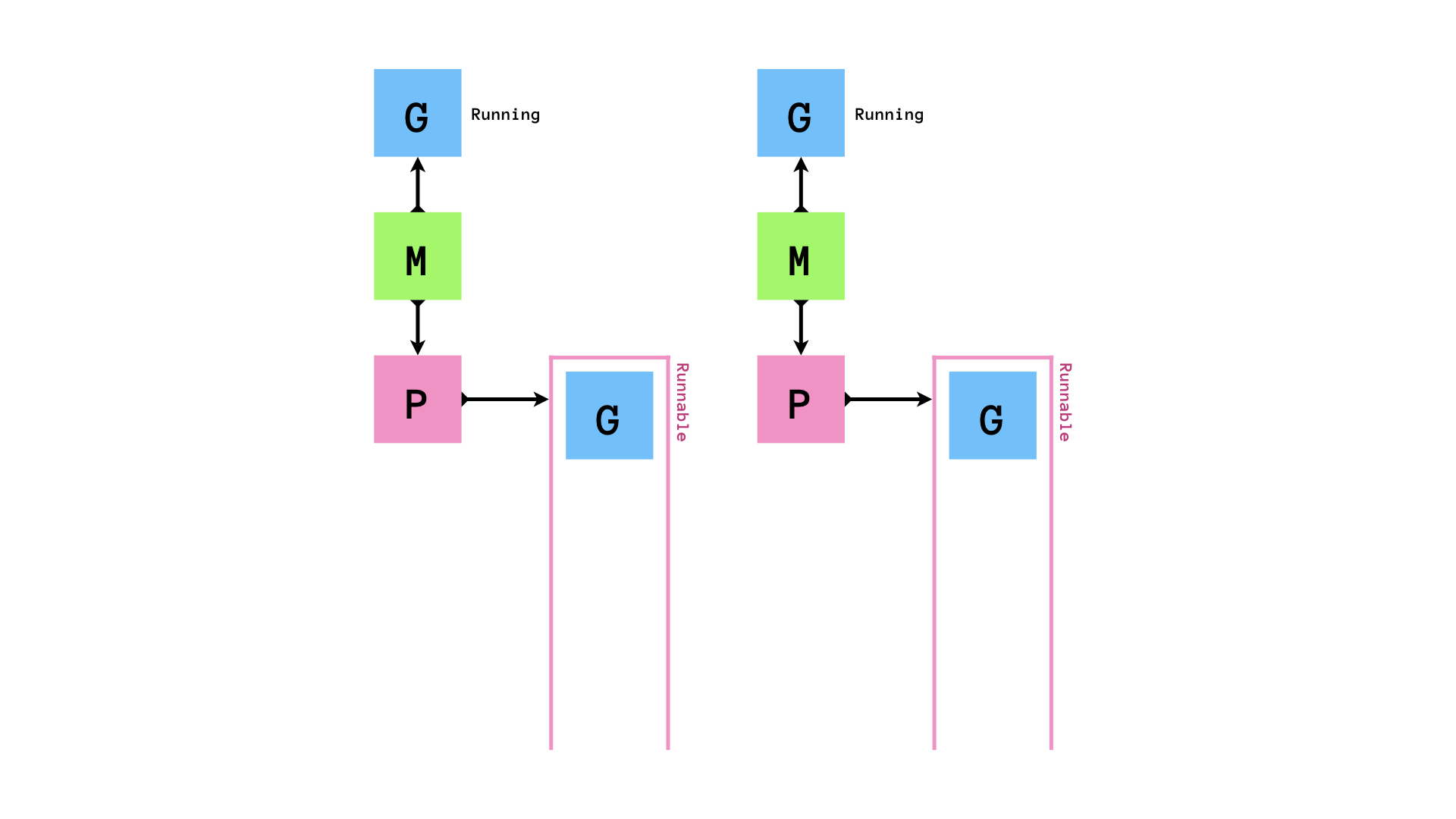
runnableなGがPにenqueueされ,MはPからrunnableなGを1個取り出して実行します.
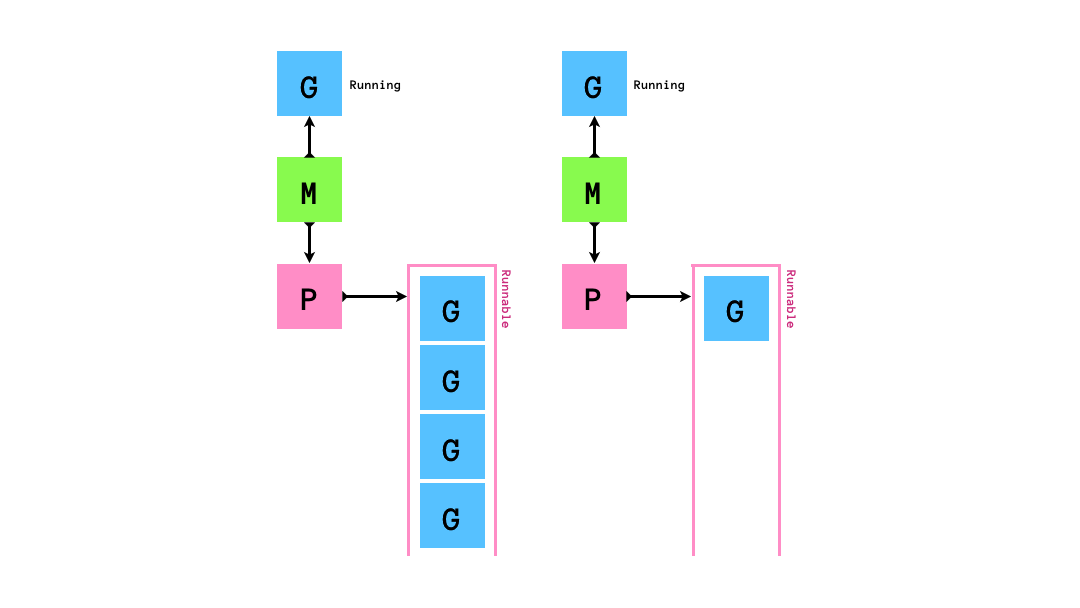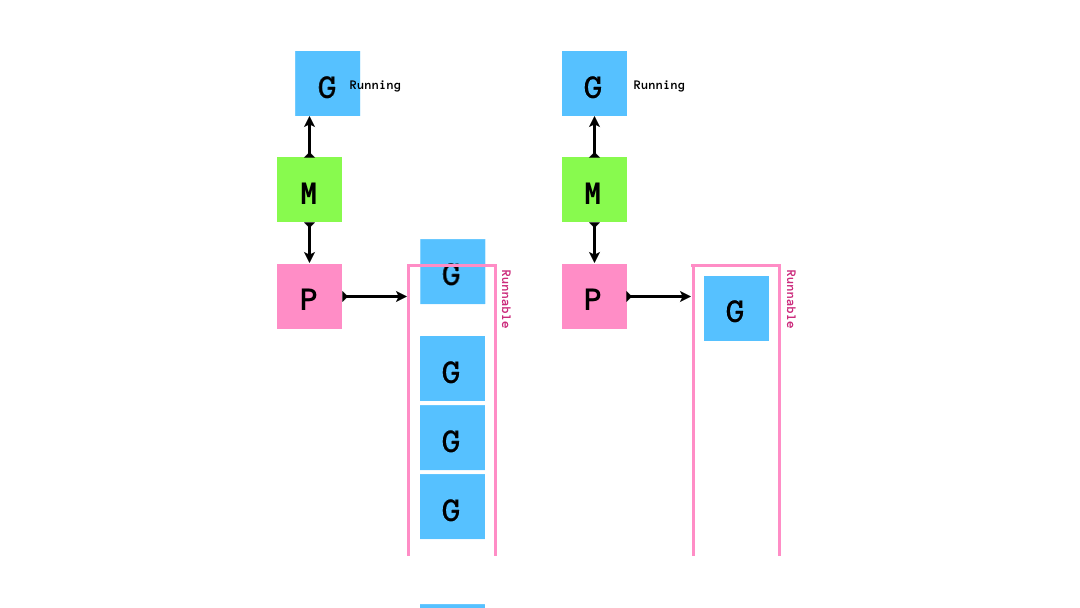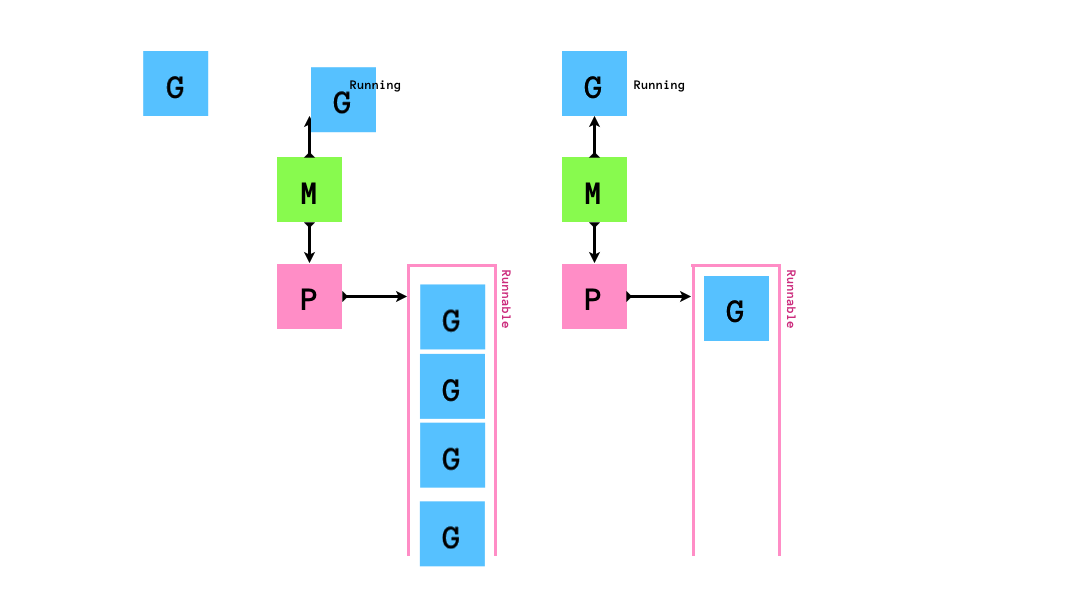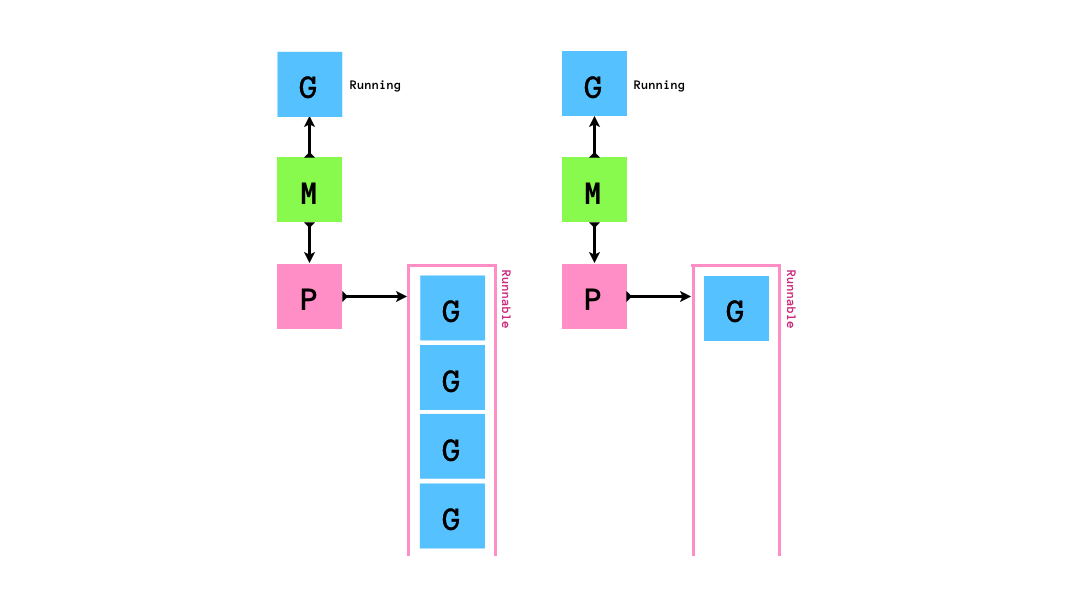
もし,queueにrunnableなGが0個になってしまったら,他のqueueから半分盗みます.
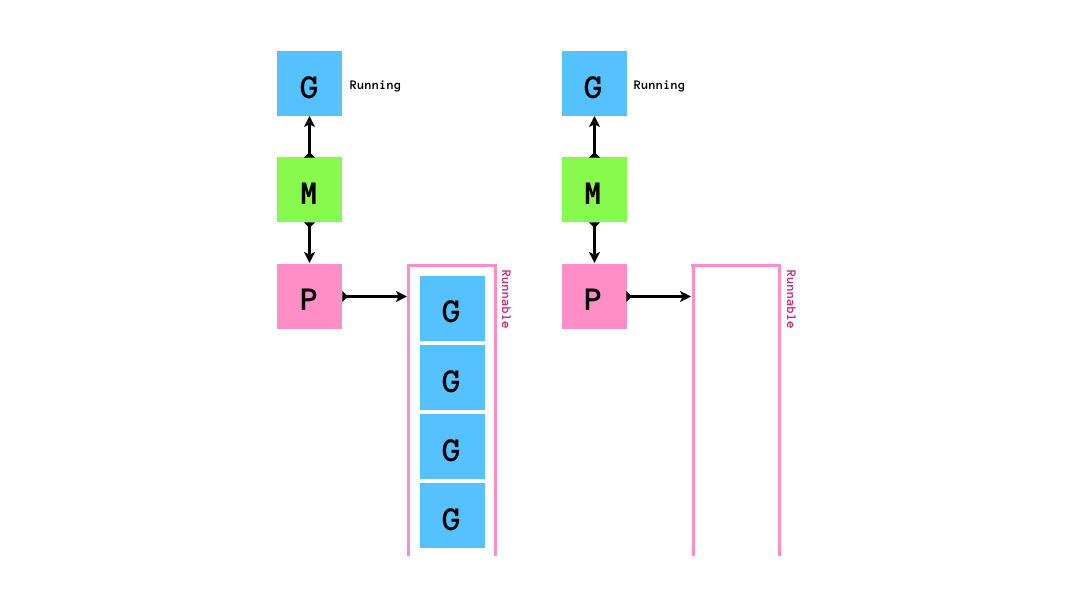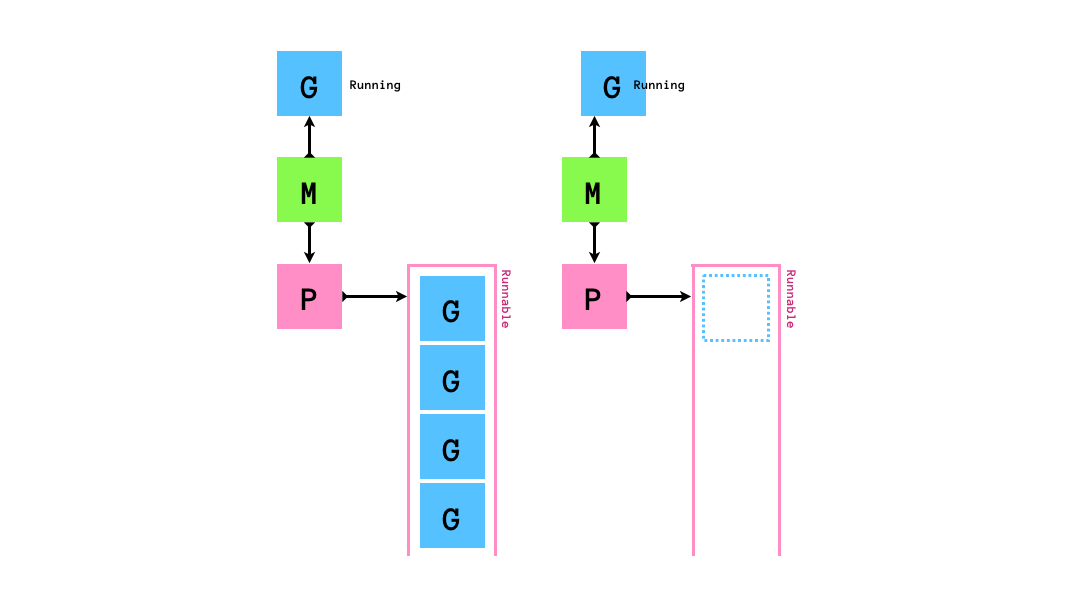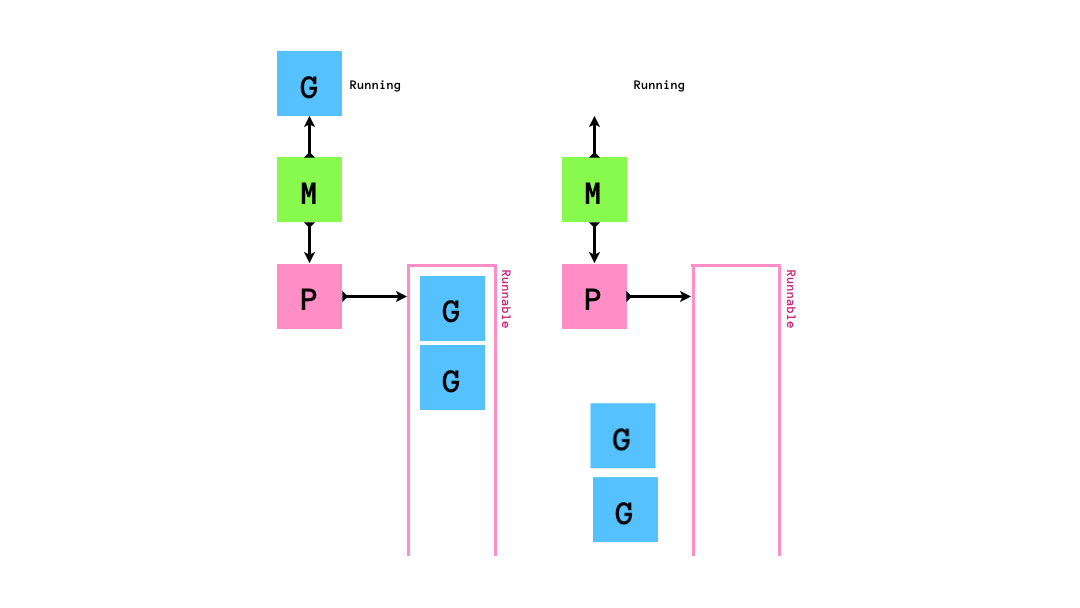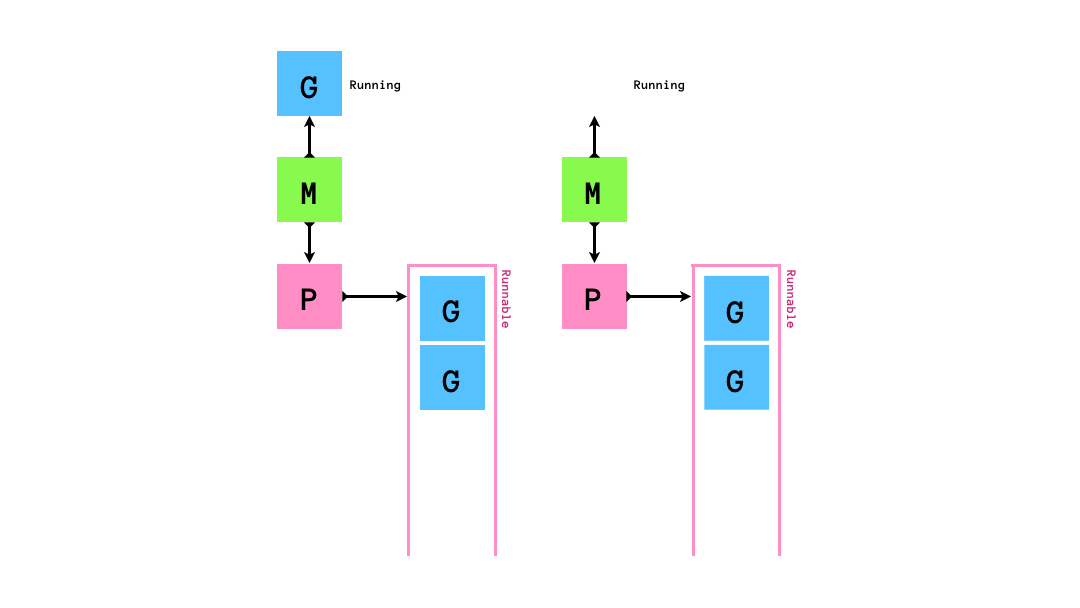
「自分のqueueが空になったら他のMの持つPから半分奪う」というスケジューリングアルゴリズムはwork stealingアルゴリズムと呼ばれています.golangのruntimeのスケジューラーはこのwork stealingアルゴリズムに従ってgoroutineのスケジューリングを行います.このアルゴリズムはCPUをたくさん使うような処理にスケジューリングには効率的である一方でI/O待ちを伴う処理(syscallの実行やネットワーク処理)とは相性が悪いです.そのため,いくつかの工夫がされています.
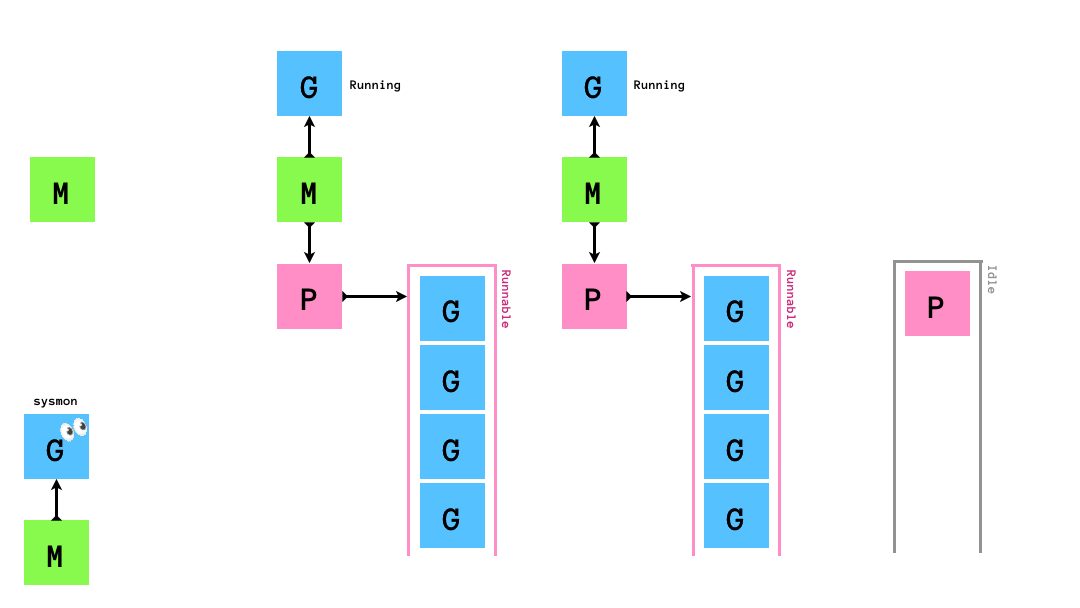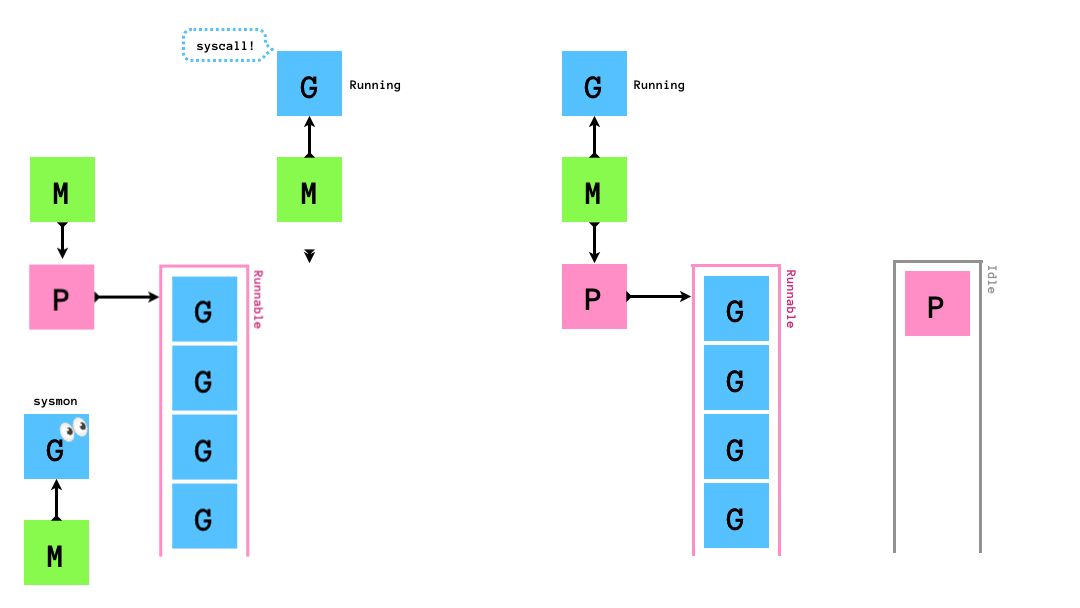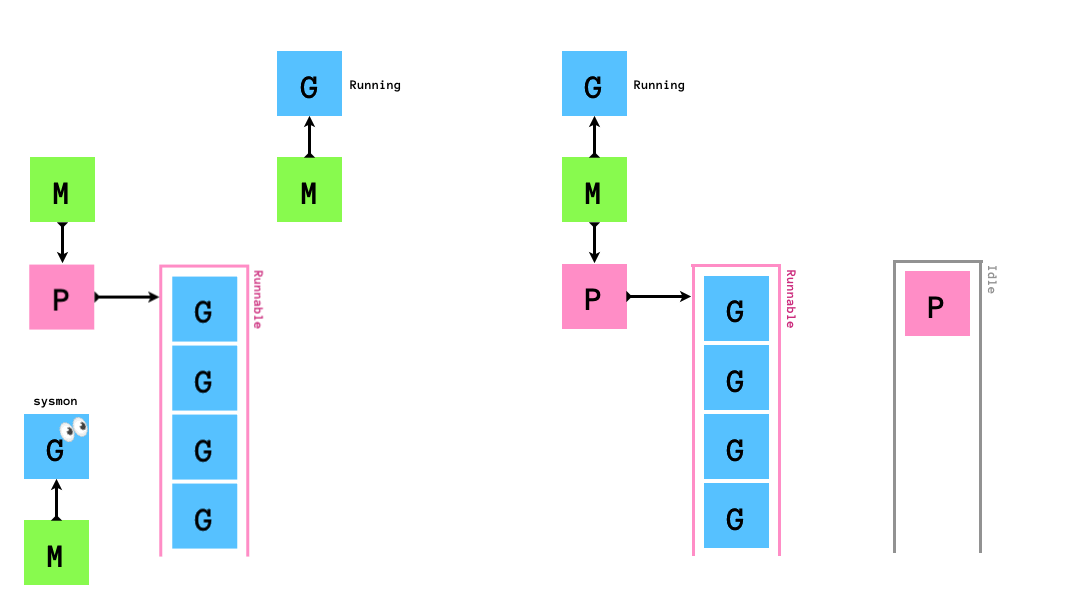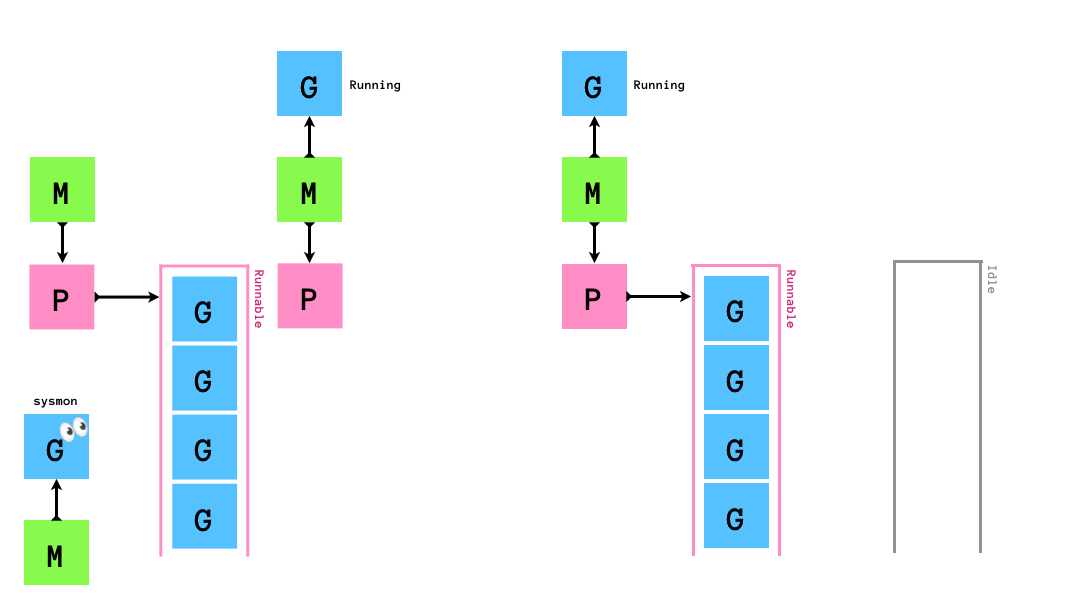
まず,golangのruntimeに存在しているものを整理します.上で登場したM,G,Pの他にruntimeには
- グローバルキュー
- 各
M-Pに対応するqueueとは別に存在するキュー - 通常
GがrunnableになるとPの持つキューに入るが,いくつかの状況ではこちらに入ります
- 各
sysmonGOMAXPROCSの数だけのMとPの他に,sysmonという関数を実行し続ける特別なMが存在していますsysmonの実態は無限ループで,そのループの中でnetpollのチェックなどを行っています
PIdle List- 暇な
Pのリスト
- 暇な
MIdle List- 暇な
Mのリスト
- 暇な
#
syscallを実行した場合
時間のかかるsyscallを実行した場合,sysmonがそれを検知し,syscallを発行したGを実行しているMからPを切り離し,別のMにそのPをアタッチして処理を継続させます.
syscall終了後は,まずP Idle Listを確認して暇そうにしているPを自身(M)にアタッチして処理を進めます.P Idle Listがからの場合はsyscallを発行したGをグローバルキューに突っ込み(このGはいずれGCされる),自身(M)はM Idle Listに入ります.
# ネットワーク処理をした場合
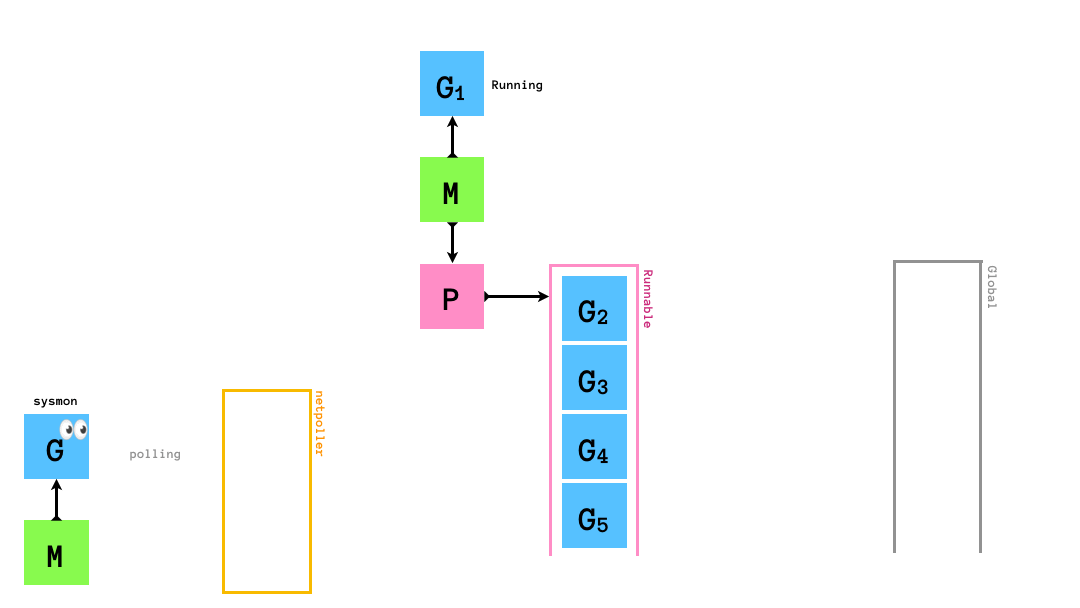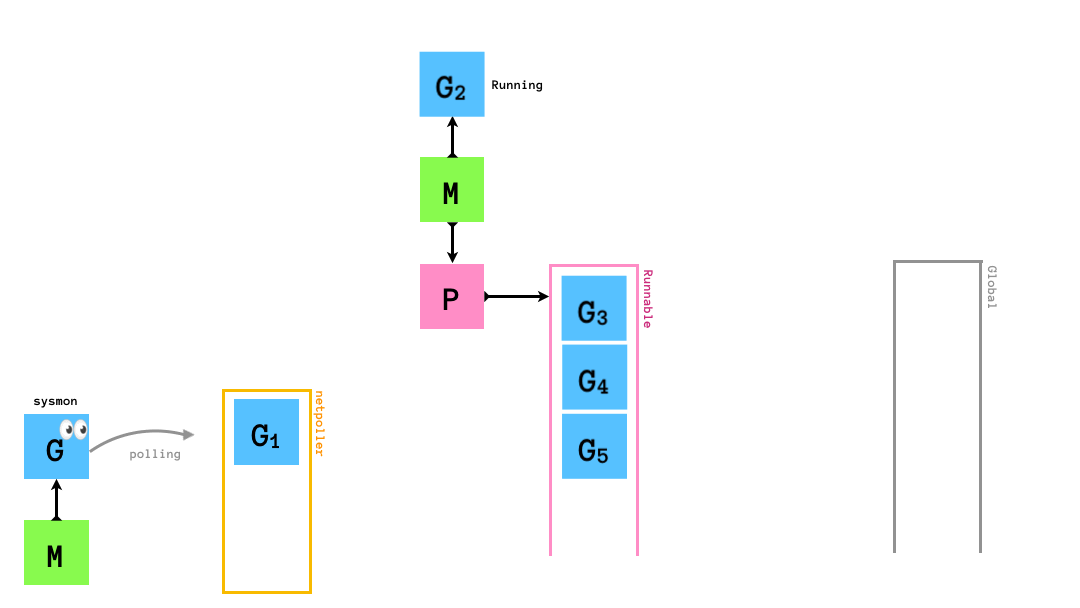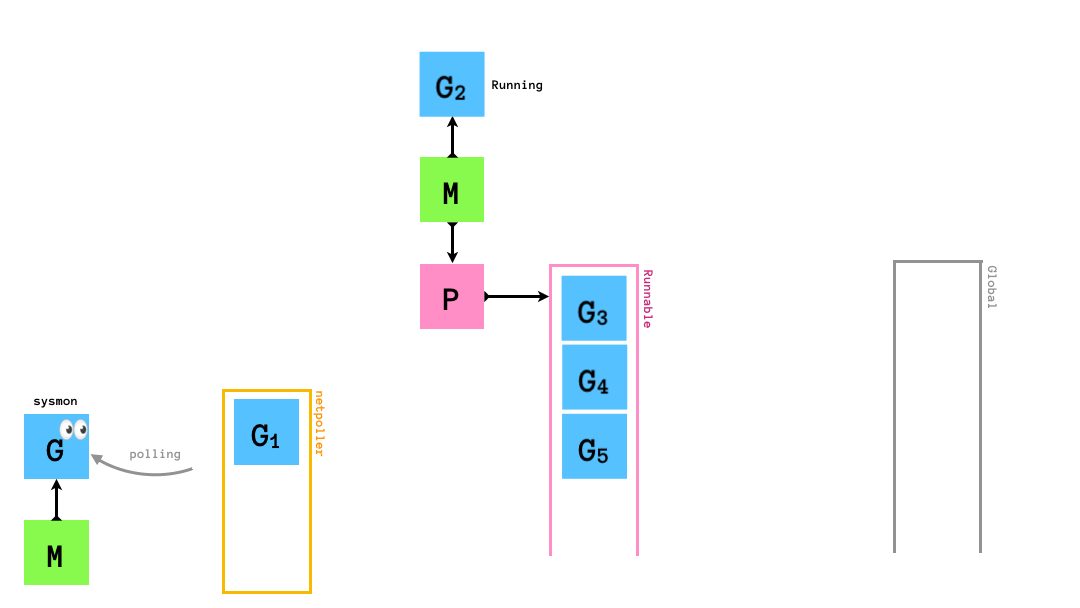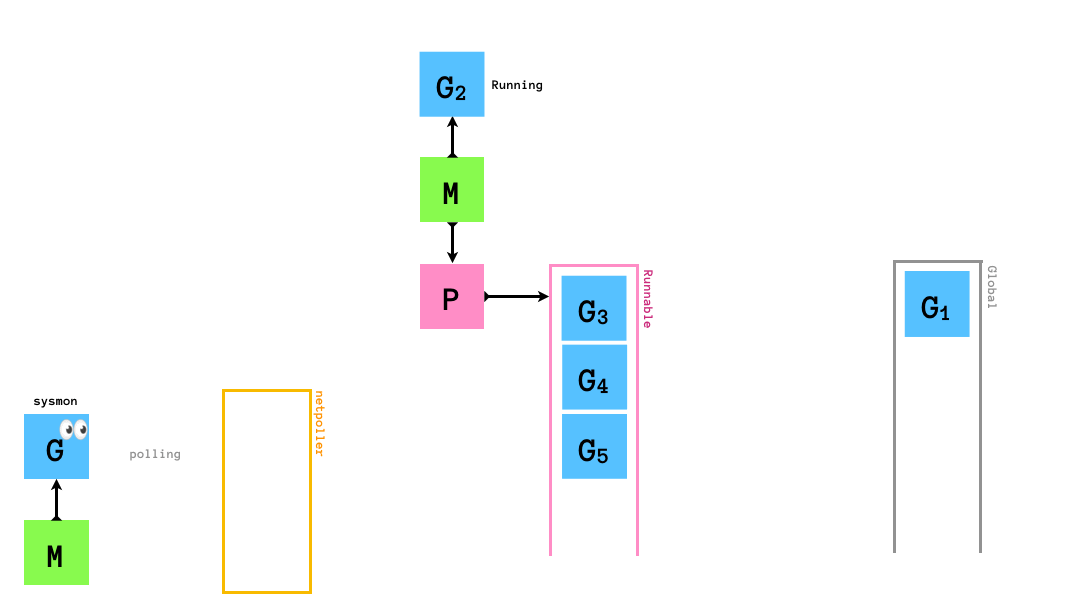
ネットワーク処理の発生時にはnetpollerという仕組みに,ネットワーク処理を実行しているgoroutineが登録され,sysmonがnetpollerにポーリングします.ネットワーク処理が終了したらnetpollerからグローバルキューに追加されて,Mで続きを実行されるのを待つことになります.
golangの標準ライブラリが提供するネットワーキングのAPIはブロッキングな処理となっていますが,goroutineはOSスレッドに対してM:Nでマッピングされるため,netpollerをによってノンブロッキングな処理として実行されることになります.
# channel
channelはgoroutine間でのメッセージングをサポートするキューです.channelにはいくつかの面白い特徴があります.
- channelはgoroutine-safe
- 複数のgoroutineがあるchannelに同時にアクセスしても問題が発生しないようにロック機構が組み込まれています
- channelはgoroutine間でFIFOなデータの受け渡しが可能です
- channelはその状況次第ではgoroutineをブロックしたりアンブロックしたりできます
- バッファ0のchannelはgoroutineを同期させることができます.つまりあるgorotuineがchannelに書き込むと,相手のgoroutineがそれを読み込むまで書き込んだgoroutineの実行はブロックされるし,channelから読み込みたいgoroutineの実行は,相手のgoroutineが何かを書き込むまでブロックされます.
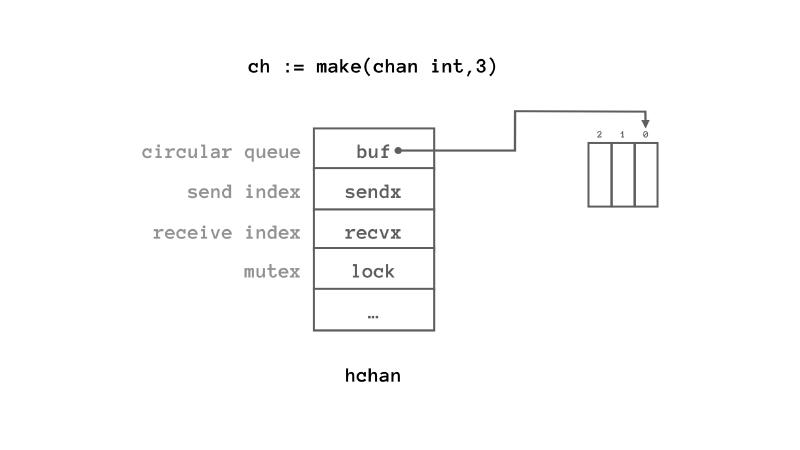
channelはhchanという名前の構造体で実装されています.
| |
まず,構造体hchanのメンバーとしてlock mutexが見えるので,channelはgoroutine-safeです.複数のgoroutineが同時にアクセスしても問題が発生しないようになっています.goroutineがchannelに対して読み書きをしたくなったらロックを取ってから行うようになっているということです.
上に示した通り,channelの実体は「circular queue(へのポインタ)」です.組み込みのmake()でchannelを作ると,実体はheap領域に確保され,それへのポインタが返されます.bufがバッファ先頭へのポインタで,sendx・recvxがそれぞれキューの先頭とお尻の番号になっています.
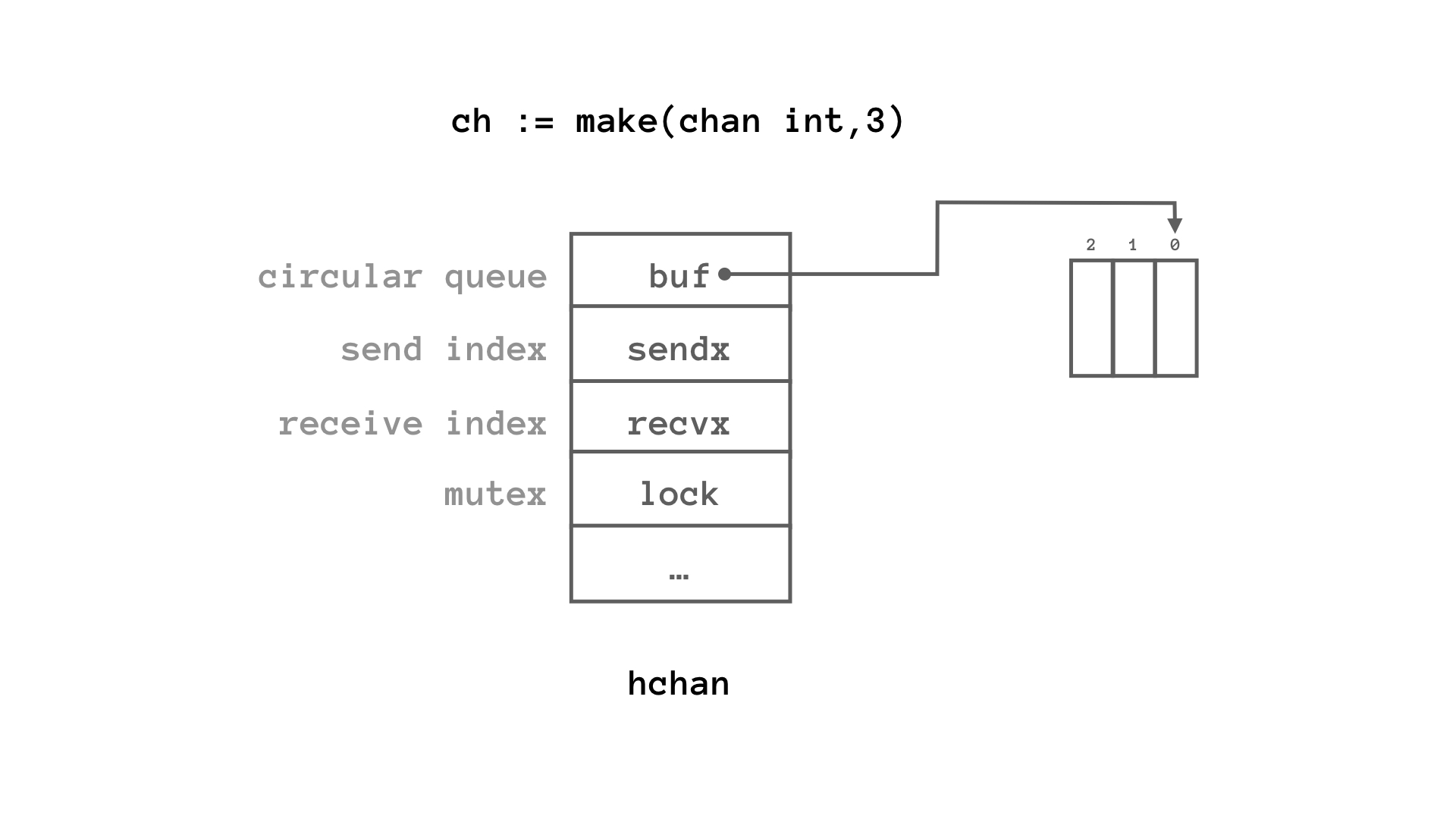
構造体`hchan`
なので,channelにメッセージが送り込まれたら,buf[0]にメッセージが入り,sendxがインクリメントされて1になります.続けてメッセージが2個送り込まれるとbuf[1],buf[2]にメッセージが書き込まれ,sendxが0に戻ります.ここでメッセージが1個読まれるとbuf[0]の内容がdequeueてrecvxが1になります.特に難しいことはなく,一般のcircular queueの動作ですね.
channel間のメッセージングはとても直感的に実現することができます.channelにメッセージを書き込む時は,まずhchanのロックを取って,次にbufのお尻に送りたいデータをメモリコピーして,アンロック.channelからメッセージを読み込む時は,同様にまずhchanのロックを取って,bufの先頭をメモリコピーして,アンロック.とてもシンプルな動作です.
実はこの挙動こそが,golangの
Don’t communicate by sharing memory, share memory by communicating.
を実装している箇所と言えます.
goroutine間で共有しているのは構造体hchanだけです.しかもhchanはロックによって排他処理が施されるため,goroutine-safeです.hchanのbufに値を書き込む(つまりchannelに値を送る)・値を読み込む(つまりchannelから値を取り出す)動作は全てメモリコピーで行われます.goroutine間でやり取りする情報は(メモリを共有するのではなくて)メモリコピーして渡しましょうというのが,上の標語の実装と言えます.
channelはgoroutineの挙動をブロックしたりアンブロックしたりすることができます.バッファに空きが無いchannel(バッファ0のchannelや容量一杯データが書き込まれているchannel)に対してデータを送り込もうとすると,gopark()が実行されます.この関数は,golangのruntimeのスケジューラを呼び出して,バッファに空きが無いchannelにデータを送り込もうとしたgoroutineの状態をwaitにして別のgoroutineの実行を始めます.channelに対してデータを送り込むロジックの中に,goroutineをブロックするロジックが組み込まれているということになります.では,どうやってブロックされたgoroutineの実行を再開するのでしょうか.
ここで興味深いのが,gopark()の実行の直前に「どのgoroutineがどんな値を送り込もうとしていたのかをchannelの中に記録しておく」というところです.構造体hchanにはsendq,recvqというメンバがあり,そこに「このchannelにどのgoroutineがどんなデータを送り込もうとしているのか,取り出すのはどのgoroutineでどこに読み込もうとしているのか」という情報を保持しています.「このchannelにどのgoroutineがどんなデータを送り込もうとしているのか,取り出すのはどのgoroutineでどこに読み込もうとしているのか」を保持する構造体はsudogという名前になっています.なぜこの名前なのかはここのメーリスの一連の流れを読むとわかるかもしれませんよ.
| |
gopark()によって受け取り手のgoroutineの実行が開始されると,受け取り手のgoroutineが,channelのsendqの中身を確認して,実行をブロックされてしまった送り手のgoroutineが最後にchannelに送り込もうとした値を(送り手側に代わって)受け取り手側がchannelのbufにコピーします.これはある種の最適化です.真面目に,送り手側の実行が再開されてからchannelにデータを送り込むことにするとchannelに対するロックを取る必要があり,排他処理をする回数が1回増えてしまいます.「誰がどんな値を送ろうとしていたのか」が自明であるならば,先にやってしまえという考えのようです.
channelから値を1個受け取ると,goready()が実行されて,スケジューラーが起動し,バッファに空きが無いchannelにメッセージを送ろうとしたgoroutineの状態をrunnableにセットして実行待ちのキューに入ります.
goroutineが空のchannelに対して読み込みを行おうとすると,そのgoroutineの動作はブロックされます.この挙動はchannelからデータを受け取るロジックであるrecv()関数内に記述されています.さらに面白いのが,「どのgoroutineが,どこに値を受け取ろうとしていたのか」をrecvqに保存していることです.これによって,channelにデータを送り込むgoroutineが,受け取り先のgoroutineのスタック領域を直接いじってデータを送り切ってしまうことが可能となります.goroutineの実体は(雑に言えば)stackを持つ構造体で,OSプロセスのスタック領域に置かれています.つまり別のgoroutineの持つstackを直接いじることが,channelでのデータのやり取りの限られた状況においてのみ許されているというのが興味深いです.
golangのchannel周りの実装を見て,
- 「排他処理を含む簡潔な実装の方が,排他処理なしの複雑な実装よりマシ.いくらパフォーマンスが良くても,それが複雑なコードでも良いことの理由にはならない」
- 「パフォーマンスの観点から,goroutineというユーザーレベルのスレッドを実装し(OSスレッドをブロックさせない),異なるgoroutineを跨いだメモリコピーを許す(その分実装がやや複雑になるがそれは許容する)」
という相反する考えが感じられます.つまり
simplicityとperformaceには明確なtrade-offが存在する
ということですね.
# おわりに
今回初めてruntimeをじっくり読みました.今まで概念として理解していたものの実体をコードとして掴めたので,とても楽しかったです.今回はgoroutineとchannel周りが中心だったので,次はスケジューラー周辺をもっとつぶさに見ていきたいと思います.